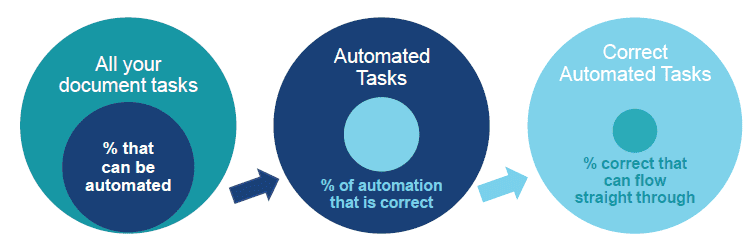
If the system can't tell between accurate and inaccurate data, then you're going to have only a small percentage of that data flow straight through, leaving the remainder of task to be completely manually reviewed.
There are many reasons why the actual system performance fails to meet expectations. While we always want a 100% perfection, the reality is that within a configuration, or setting up an intelligent capture system, there are many steps that must be completed very well.
The first step is data preparation, which consists of understanding the scope of your documents, not only the number of documents that you'd like to automate but also the characteristics of those documents:
Is there a high degree of variance in terms of image quality or data layout?
Anything that affects the amount of comprehensiveness in terms of when you create and configure a system?
Is it going to know how to deal with the documents?
Once you have the wide array of samples that you want to build a system around, you must take the time to configure it. Configuration can often require technical capabilities, and that often requires a significant amount of investment. The next step is testing and tuning, which is an iterative process of testing your output and optimizing it. Once you get it into production, the unfortunate reality is that things change. Documents change. Layouts change. You onboard a new client or customer who has a new type of document, for example, and this means you have to go through all these steps again.